This post is part of the complete Guide on Python for SEO
For years SEOs have clambered on about how keyword density is dead.
For keyword ranking perhaps, but it’s still a useful tool in determining a web page’s identity.
If your top ten most used keywords don’t align with your target identity then something is off. For pages I’ve never seen before, I’ll calculate the top ten most frequently used words and if I can’t quickly determine what the page is about, something is wrong.
In this step-by-step tutorial, I’ll show you how to calculate the word frequency for each page and sitewide using Python.
Here is an example of what you will get.
For a bonus, we’re going to tap into the Google Knowledge Graph API and label each if detected as a known entity.
Requirements and Assumptions
- Python 3 is installed and basic Python syntax understood
- Access to a Linux installation (I recommend Ubuntu)
- Google Knowledge API Key
Install Libraries
First, let’s install fake_useragent for the website requests and Beautiful Soup for the web scraping.
$ pip3 install fake_useragent
$ pip3 install bs4
Import Modules in the Script
Next, we import our required modules.
We need requests and fake_useragent to call each web page. BS4 to scrape the words from the page. Collections to count the number of each word. Pandas and io if you want to run using a CSV of URLs, and time for script delays.
import requests
from bs4 import BeautifulSoup
from collections import Counter
import pandas as pd
import time
import io
from fake_useragent import UserAgent
Load the URLs to Scan
You have 3 options for how to load the URLs that will be processed.
- Option 1 is to load them from an external CSV.
- Option 2 is to load a local CSV.
- Option 3 is to load a Python list. If from a CSV we’ll convert them to a Python list.
Option 1: Load From External CSV
In this script, replace CSV_URL with the URL where the CSV is hosted.
excsv = requests.get('CSV_URL').content
crawldf = pd.read_csv(io.StringIO(excsv.decode('utf-8')))
addresses = crawldf['Address'].tolist()
Option 2 : Load From Local CSV
In this script, replace LOCAL_PATH_TO_CSV with the path where the CSV is saved on your computer.
crawldf = pd.read_csv('LOCAL_PATH_TO_CSV')
addresses = crawldf['Address'].tolist()
Option 3: Load From Python List
addresses = ['URL1','URL2','URL3']
Set-Up the HTTP Request User Agent
Now let’s use the fake_useragent module to generate a user agent for us to use in our header for each web page request.
ua = UserAgent()
headers = {
'User-Agent': ua.chrome
}
Create a Function for the Knowledge Base API
Before we process any URLs, let’s set up a function to handle the Google Knowledge Base API calls.
This function takes a single keyword that will be generated using the word frequency that we calculated.
For the url variable, make sure to replace the key parameter with your API key.
Use the response variable to make the call and stores the response. Use the JSON module loads() function to create a Python dictionary object and load it into data.
Then, we can try to access the entity labelling property and capture that data into getlabel.
defgkbAPI(keyword): url="https://kgsearch.googleapis.com/v1/entities:search?query="+keyword+"&key=YOUR_API_KEY&limit=1&indent=True" payload={} headers={} response=requests.request("GET", url, headers=headers, data = payload) data=json.loads(response.text)try: getlabel=data['itemListElement'][0]['result']['@type']except: getlabel=["none"]returngetlabel
Scrape the Web Pages With Requests
Now, we create an empty list variable to store the site-wide data.
After that, we start our for loop of the URLs in the addresses list.
To avoid getting blocked by server security we set a 1-second delay between the processing of each URL. We set url to the current URL in the addresses list. We then use the requests module to get the URL contents and load them in the html_page variable.
fulllist = []
for row in addresses:
time.sleep(1)
url = row
print(url)
res = requests.get(url,headers=headers)
html_page = res.content
Parse the HTML of Each Page
Now that we have the URL contents we can load into a BS4 object we’ll name soup. Using the find_all() function we’ll extract only the text between HTML tags with the text=True parameter.
soup = BeautifulSoup(html_page, 'html.parser')
text = soup.find_all(text=True)
Remove Stopwords
Processing all words is a waste of resources when we know we only primarily want nouns and verbs.
So let’s create a list of stop words we will filter out. This is a basic list, feel free to add more that you find sneaking in.
stopwords = ['get','ourselves', 'hers','us','there','you','for','that','as','between', 'yourself', 'but', 'again', 'there', 'about', 'once', 'during', 'out', 'very', 'having', 'with', 'they', 'own', 'an', 'be', 'some', 'for', 'do', 'its', 'yours', 'such', 'into', 'of', 'most', 'itself', 'other', 'off', 'is', 's', 'am', 'or', 'who', 'as', 'from', 'him', 'each', 'the', 'themselves', 'until', 'below', 'are', 'we', 'these', 'your', 'his', 'through', 'don', 'nor', 'me', 'were', 'her', 'more', 'himself', 'this', 'down', 'should', 'our', 'their', 'while', 'above', 'both', 'up', 'to', 'ours', 'had', 'she', 'all', 'no', 'when', 'at', 'any', 'before', 'them', 'same', 'and', 'been', 'have', 'in', 'will', 'on', 'does', 'yourselves', 'then', 'that', 'because', 'what', 'over', 'why', 'so', 'can', 'did', 'not', 'now', 'under', 'he', 'you', 'herself', 'has', 'just', 'where', 'too', 'only', 'myself', 'which', 'those', 'i', 'after', 'few', 'whom', 't', 'being', 'if', 'theirs', 'my', 'against', 'a', 'by', 'doing', 'it', 'how', 'further', 'was', 'here', 'than']
Filter Non-Relevant HTML Tag
We also want to filter out any text from between certain HTML elements that aren’t relevant to on-page content. Again, feel free to add on to this list. Some sites need more filters than others depending on their design framework.
output = ''
blacklist = [
'[document]',
'noscript',
'header',
'html',
'meta',
'head',
'input',
'script',
'style',
'input'
]
Filter Special Characters
Certain characters can hitch a ride into our results that we want to filter out. Add on to this list as you see fit.
ban_chars = ['|','/','&']
Merge Keywords into a String
It’s time to start creating our list of words from the web text into a giant string. Starting with removing the text from within HTML tags we added to our blacklist and removing newline and tab characters. Once we have our long string of text we create a list separating by a space.
for t in text:
if t.parent.name not in blacklist:
output += t.replace("\n","").replace("\t","")
output = output.split(" ")
Apply Filters to Clean the Word List
Now that we have our word list, it’s time to sanitize it a bit by removing the stopwords and characters we don’t want.
The first list comprehension removes the characters, the second list comprehension sets all characters lowercase and the second removes the stopwords.
What is left is a pretty good set of words which for each page is store in the variable output. To keep track for site-wide stats we will dump the words into the variable fulllist for every page.
output = [x for x in output if not x=='' and not x[0] =='#' and x not in ban_chars]
output = [x.lower() for x in output]
output = [word for word in output if word not in stopwords]
fulllist += output
Get top 10 Keywords Count
The time to use the Collections module has finally come. This is a real nice module.
All you need to send to the Counter() function a list of words, and it does the rest.
To keep output manageable and actionable I like to keep the output to the top 10-20 most frequent words. For that use the most_common() function.
counts = Counter(output).most_common(10)
Display the Results by Page
We now have a dictionary list of the top 10 words for each page and the count number.
It’s time to display them with a for loop. While in the loop this is the time to use the Google Knowledge Base API function we added at the beginning.
We’ll call that function and send it the key variable which contains the word.
for key, value in counts:
getlabels = gkbAPI(key)
strgetlabels = ', '.join(getlabels)
readout = str(key) + ": {:>0}" + " | Entity Labels: " + strgetlabels
print(readout.format(str(value)))
print("\n")
Now that all of the top ten word counts for each page have been displayed it’s time to display the site-wide counts.
Display the Results Site-Wide
The process is the same as for each page, but we use the variable we used to stop all page words, not just a single page like above.
print("-------- AGGREGATE COUNT -------")
fullcounts = Counter(fulllist).most_common(10)
for key, value in fullcounts:
getlabels = gkbAPI(key)
strgetlabels = ', '.join(getlabels)
readout = str(key) + ": {:>0}" + " | Entity Labels: " + strgetlabels
print(readout.format(str(value)))
Final Output
The output should look something like this.
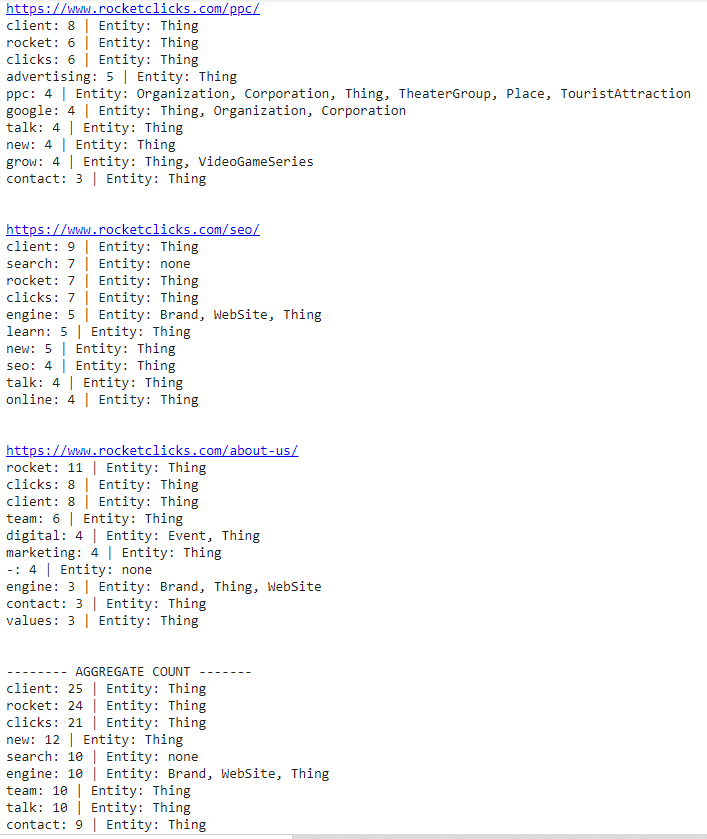
Conclusion
As you can now see calculating keyword density or word frequency can still be useful in understanding your pages and site’s identity.
From here you can extend the script to store the information in a database to track changes over time or build our functions to calculate bigrams and trigrams as single words don’t tell the whole story.

Founder of PhysicsForums.com | SEO Analyst for RocketClicks.com