How does Google handle duplicate content on the Web? One of the many ways is that they compare URL patterns to predict which ones are likely duplicated.
In this post, I will cover some of what I have learned reading the Google patent titled “Predictive-based clustering with representative redirect targets” by Jeff Cox, Mike Turitzin and David Michael Proudfoot.
What is the Patent About?
This patent is about how Google predicts duplicate documents based on URL pattern, redirect targets and content checksums.
Highlights on Predictive Clustering
Google’s Indexing System handles duplicate documents by predicting duplication based on URL patterns, by looking at redirect targets and by comparing checksums of the contents of documents.
URLs with tracking parameters, or very likely duplicate (e.g. www, non-www) will possibly be clustered together.
URLs that redirect to the same target will also be likely clustered together.
URLs for which the content’s checksum is similar enough will be clustered together.
The order may not always be the same. Sometimes, predictive clustering is done first, othertimes, content clustering is done first and then predictive clustering is performed.
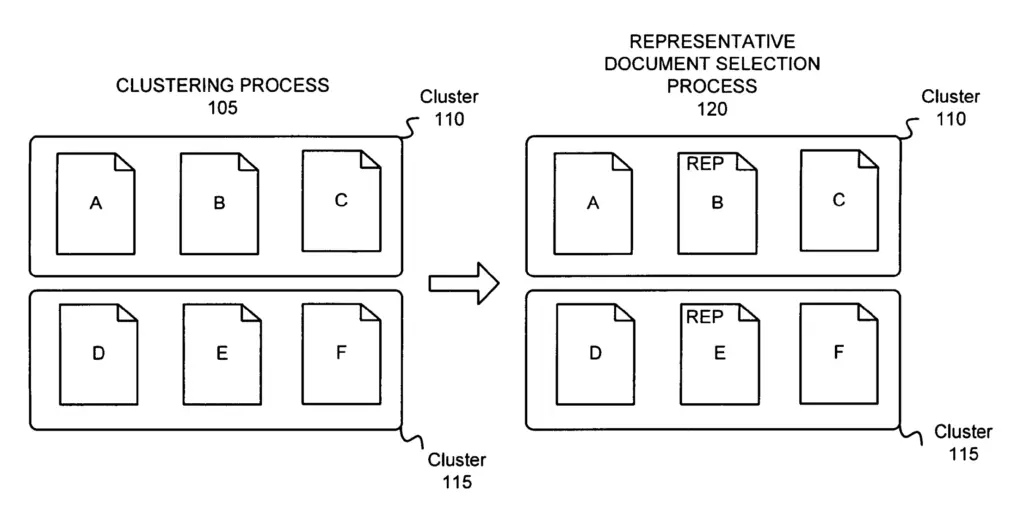
For each cluster, representative(s) of the cluster are selected based on quality score metrics.
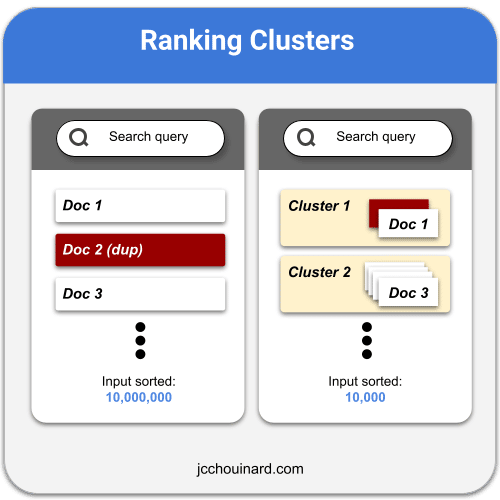
Finally, documents in a clusters are ranked in an inverted index and the canonical version is selected using the top ranked document.
Why Remove Duplicate Documents?
Indexing duplicate documents wastes space in the index, slow down retrieval speed, and may be detrimental to user experience.
To prevent wasting processing, storage and network resources, Google invests in removing duplicates at all stages of search (crawling, indexing, serving).
Clustering documents helps to provide more relevant search results, reduce amount of storage required and improve the speed of retrieval.
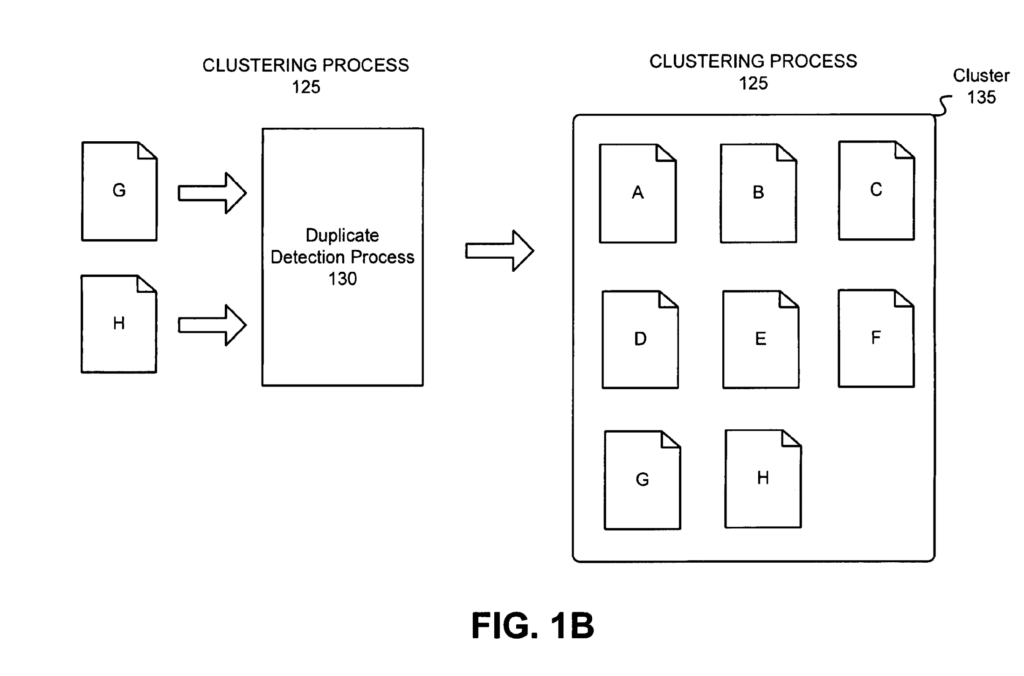
Duplicate detection can be done by various softwares or components of the search system.
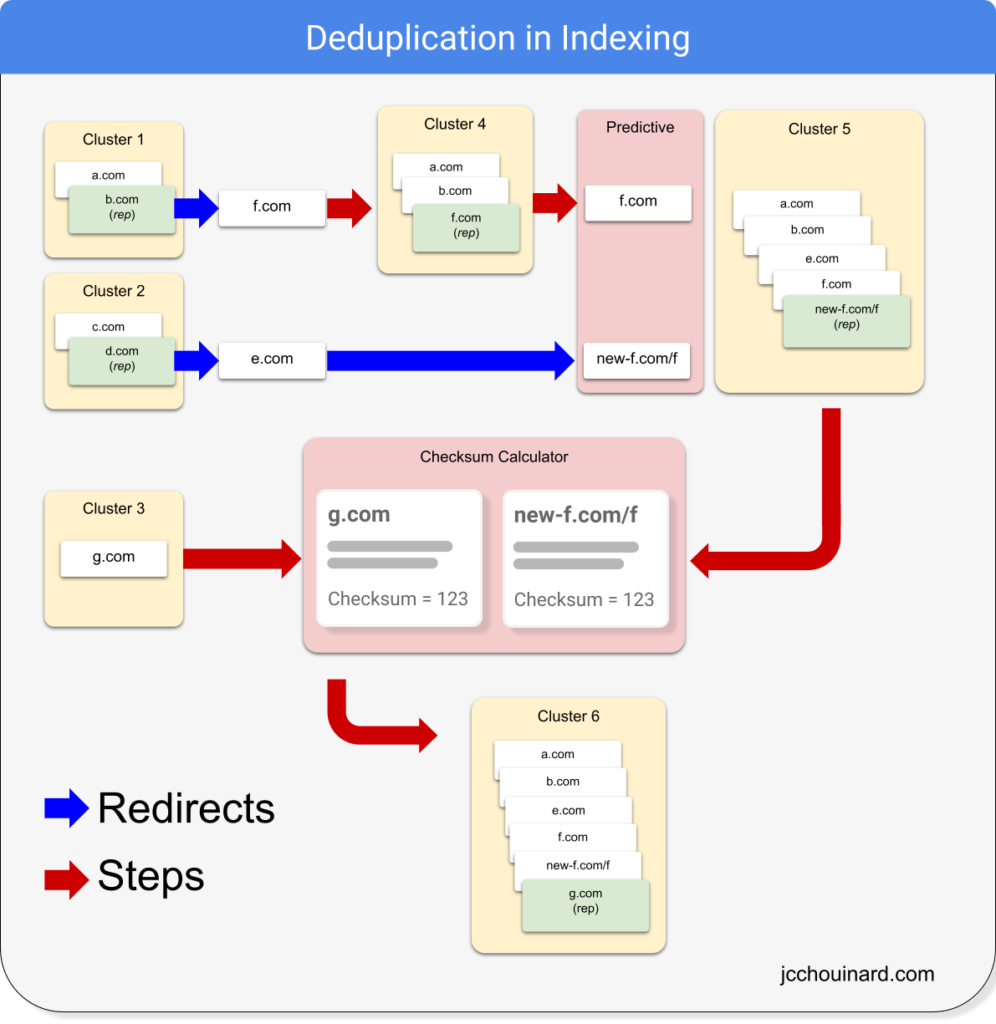
First, let’s look at what a duplicate cluster is.
What is a Duplicate Cluster?
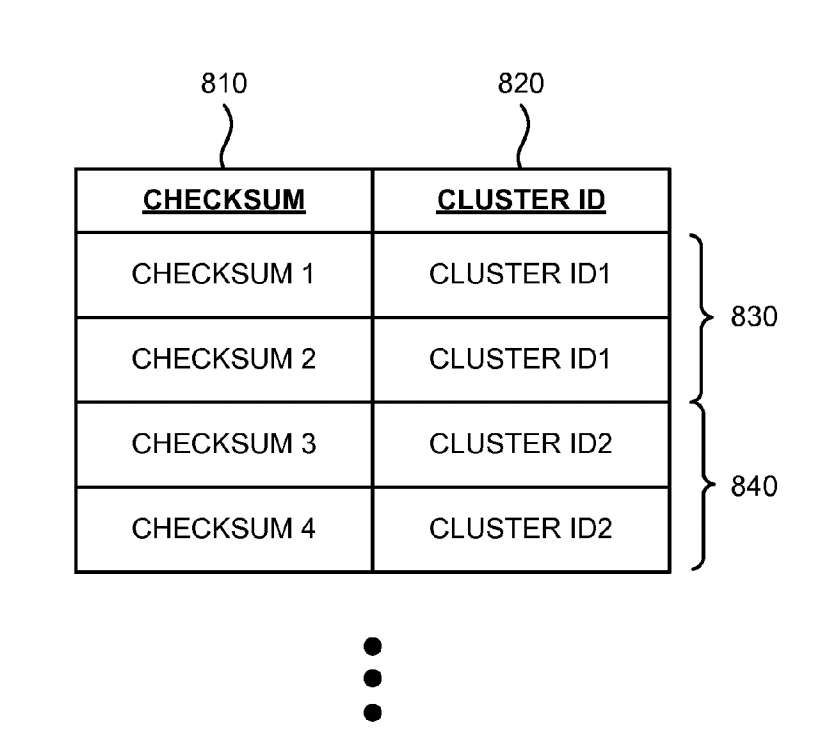
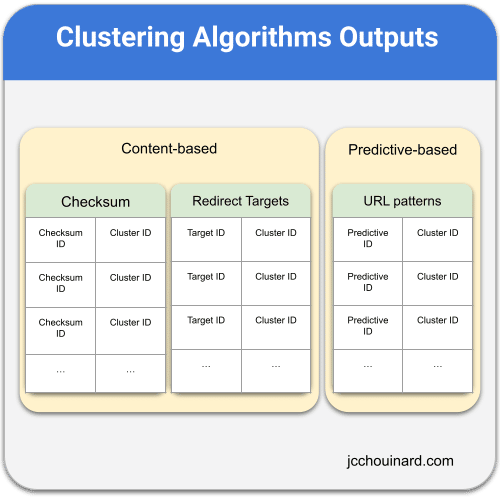
A duplicate cluster is a cluster that include one or more documents sharing the same key.
Some duplicate cluster may have different type of keys.
For example, looking at the image below, depending on what clustering algorithm is used, the left column will be different, showing the checksum ID or Target ID for content-based clustering and the predictive ID for predictive-based clustering.
Two Main Categories of Clustering Algorithms
Clustering of documents is executed by the duplicate detector using different clustering algorithms.
Each clustering algorithm is categorized whether the indexing engine needs to analyze the documents contents or not.
Here are the two clustering algorithm categories in the duplicate detection process:
- Content-based clustering (document is processed)
- Predictive-based clustering (document is not processed)
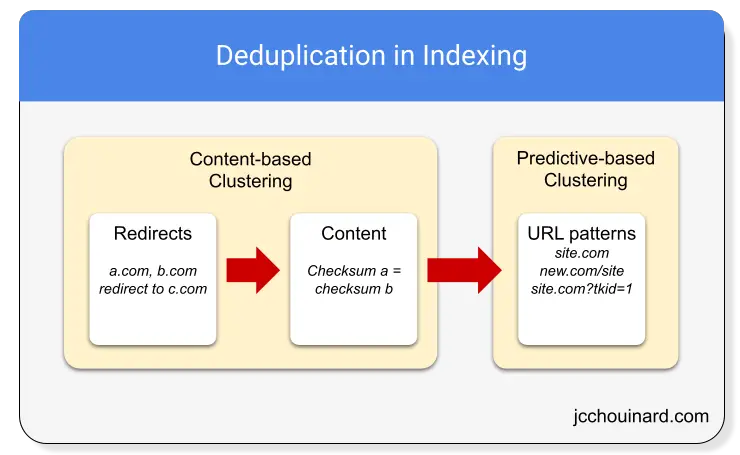
Content-Based Clustering
When trying to determine duplicate documents, Google will first look at redirections and create clusters of duplicates for documents that redirect to the same place (Target ID). Then, for each target address, it will compute the checksum on the content (Checksum ID).
Predictive-based clustering
If two web addresses (e.g. URLs) are considered equivalent based on URL patterns, they will be clustered without analyzing its content. The cluster will have a predictive ID and a cluster ID.
Three (3) Main Clustering Algorithms
There are 3 main clustering algorithms.
Two are content-based, one is predictive-based.
- Comparing content checksums (content-based)
- Comparing Redirect targets (content-based)
- Comparing URL patterns (predictive-based)
Each clustering algorithm will return a different ID that can be used in de-duplication (e.g. left column in the example duplicate cluster).
- Checksum ID (content checksums)
- Target ID (Redirect targets)
- Predictive ID (URLs patterns)
1. Checksum ID
If the difference between the checksums of the content of two documents is small enough, both documents will be clustered and given the same Checksum ID.
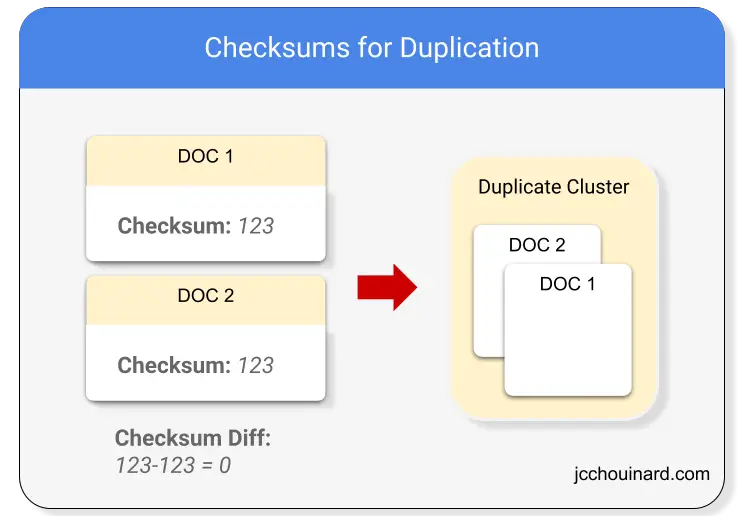
What is a Checksum?
A checksum is a number that is calculated by converting letters to bytes and summing each byte to get a fixed length value.

Checksum on Content
When processing documents, the indexer/crawler system computes the checksum on entire, or portion of, documents. Documents with identical checksums are clustered together.
Learn more about this technique reading my tutorial on how Google uses portions of a document to de-duplicate content.
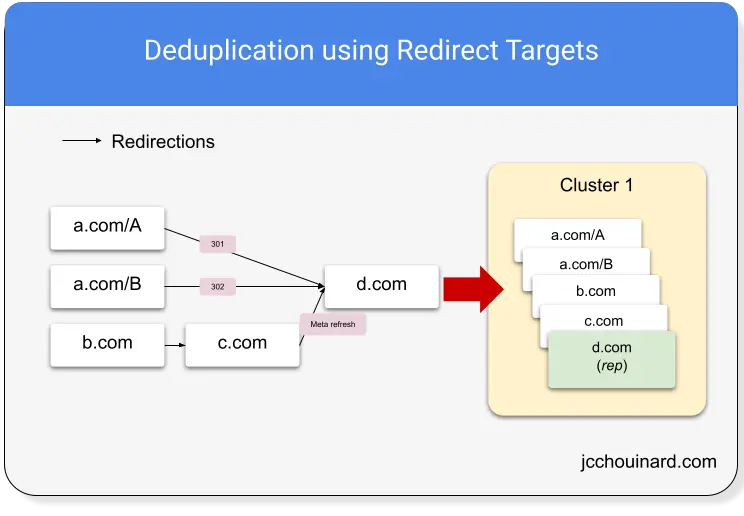
2. Target ID
If two documents redirect to the same URL, they will be clustered together and given the same target ID.
3. Predictive ID
Google’s indexing engine my identify duplicate documents using predictive techniques on URLs without analyzing the contents of the documents.
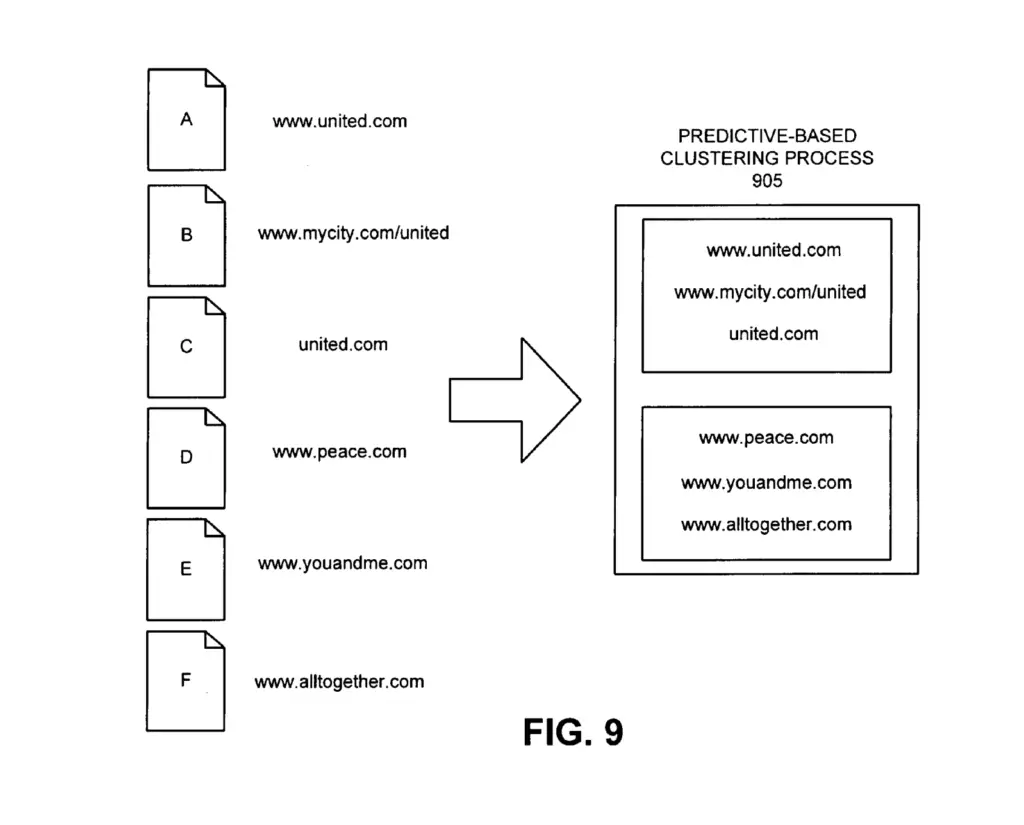
Predictive clustering identifies URL patterns that imply that two documents are the same and assign a predictive ID.
Such patterns may be:
- Address pairs (mysite.com vs newbrand.com/mysite)
- Address pairs (mysite.com/document vs newbrand.com/mysite/document)
- www/non-www URLs,
- Unimportant parameters in URLs (such as session ID).
For example, the duplicate detector may cluster all these URLs together.
https://www.example.com/blog-post-1
https://example.com/blog-post-1
https://www.example.com/blog-post-1?sid=123
https://www.newsite.com/example/blog-post-1If so, all these documents would be assigned with the same predictive ID.
Process of Clustering Documents
Below shows an example process that can be used to cluster duplicate documents. The order of the steps may be different.
1. Clustering Duplicate Documents
When Google finds duplicate documents, they group them into a duplicate cluster and assign a canonical version and cluster ID to the set of documents.
The forming of clusters is iterative. Whenever a new document is found, clusters may be split or merged together using predictive and/or content-based algorithm.
In its basic form, Google uses a hashing technique called the checksum to compare contents.
There are, however, different clustering algorithms that can be used by the indexing engine, and each output is different.
2. Selecting the Representative of a Cluster
Choosing the best document to be representative of a cluster is done by the Representative Selector.
To prevent wasting resources and degrading user experience, Google selects one document of a cluster of duplicate documents to be the canonical version of the cluster.
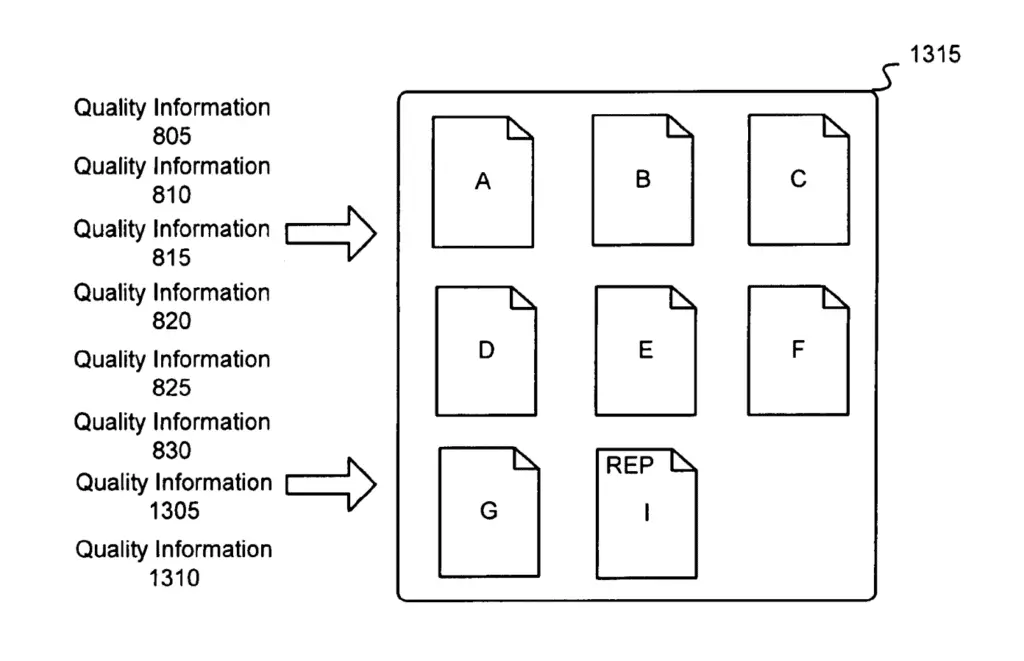
In the image below, two clusters of duplicate documents were created and the document “B” and “E” were selected to be the representative of their respective clusters.
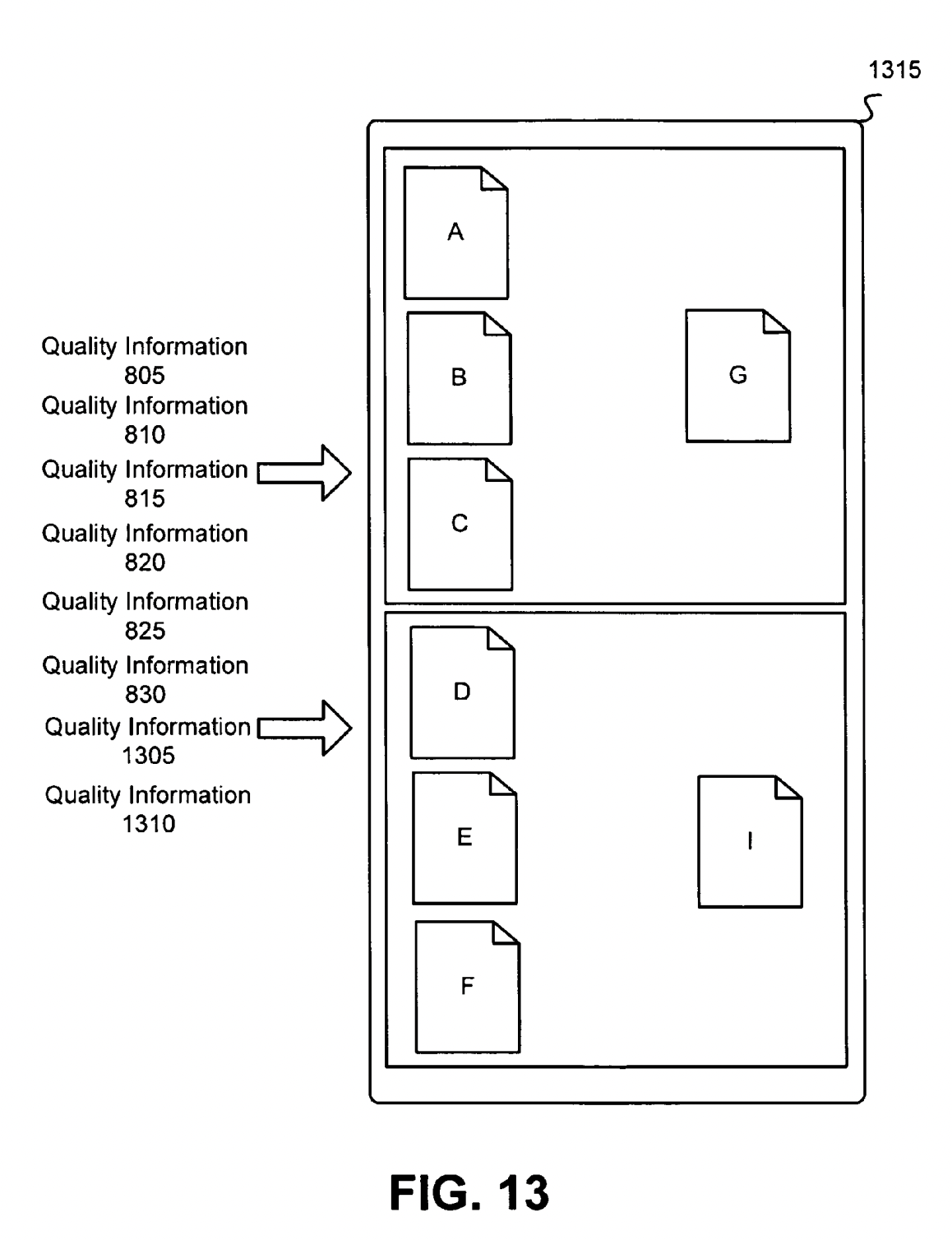
To select the document that is most representative of a cluster, the representative selector ranks the documents based on a measure of quality (e.g. quality score).
Quality Score and Quality Information
Quality of information is referred to as any information useful in scoring, indexing or serving a document.
Link-based score
- a number of links to/from a document,
- a position of a link within a document
Date a document is created
Page Rank
Anchor text information
Anaesthetic value of an address
- a short and/or a word-based URL may have a higher aesthetic value than a long and/or a non-word based URL containing, for example, symbols, such as ?, , ~, *, etc.
Measure of popularity
Quality of the website that include the document
Age of website that includes the document
3. Evaluating Redirects of the Chosen Representative
If Google ran a content-based clustering algorithm first, representatives were chosen, and then redirections are checked.
By evaluating redirect targets, Google may have discovered that documents “B” and “E” from cluster 1 and 2 are redirected to “G” and “H”.
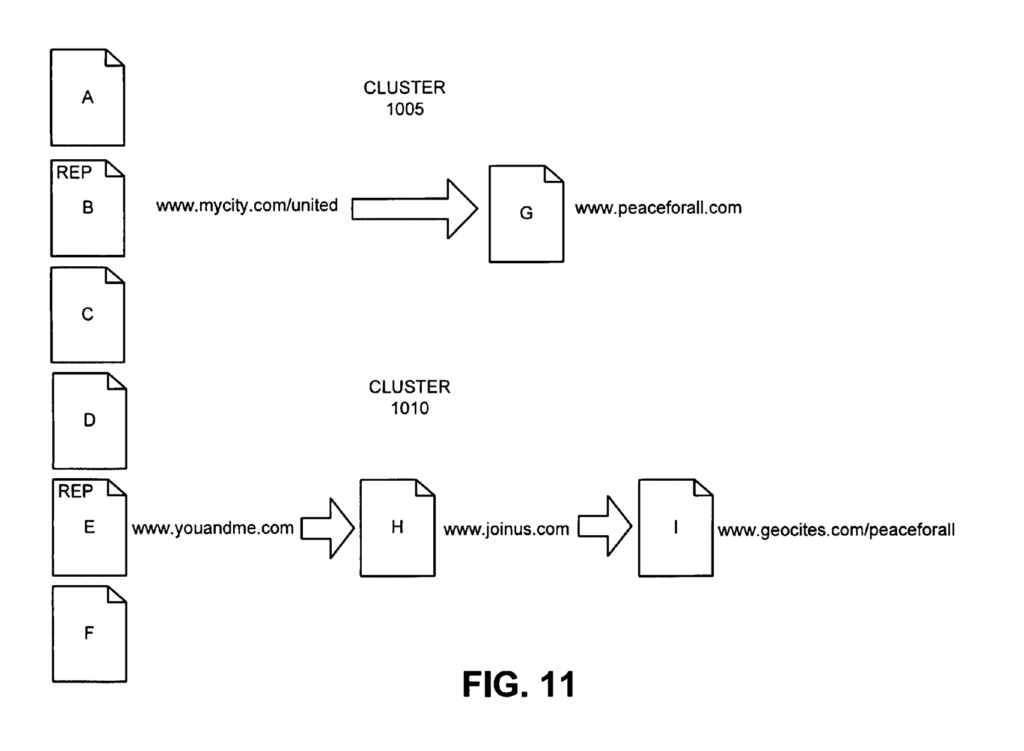
If Google finds that the target URLs “G” and “H” are duplicate, then the result may be that both clusters are merged into a single cluster.
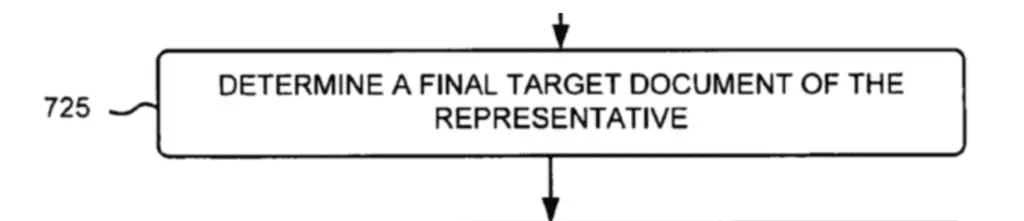
4. Evaluating Duplication of Target URLs
Once target URLs are found, Google evaluate the content of each target address to see if they are duplicate documents.

In the image below, we see the target URLs “G” and “I” being compared for duplication
5. Clustering Duplicate Clusters
Based on final targets of documents, Google re-cluster based on recently acquired information.
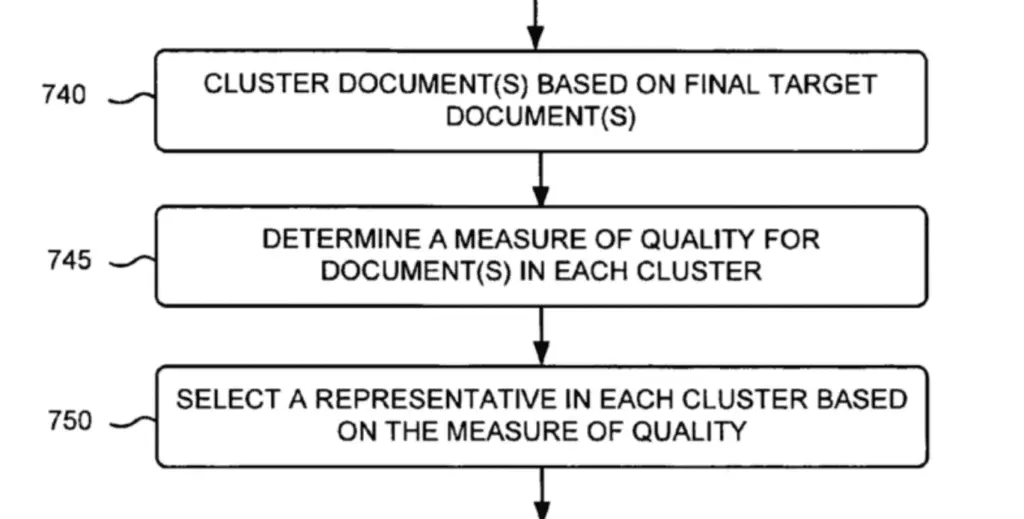
We can see in the example below that both clusters were combined in a single one and a new representative selected for the recently created cluster.
6. Indexing Clusters of Duplicates
The indexer may index one ore more of the top-ranked documents (e.g. canonicals) for each ranked lists.
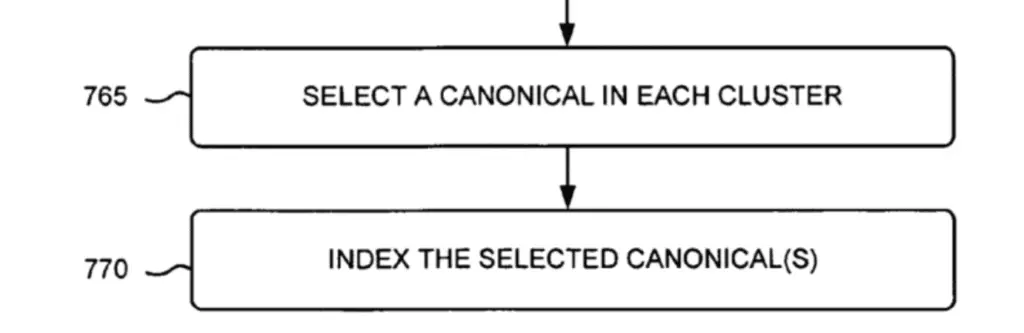
Selecting a Canonical in Each Cluster
The process of selecting the canonical may be more elaborate that selecting a representative.
Whilst selecting a representative involve checking a quality score for a document, selecting a canonical involve ranking duplicate documents in an inverted index using a quality score along with other ranking factors.
Indexing the Selected Canonical(s)
One or more of the top-ranked documents (e.g. canonical) of the cluster may be indexed.
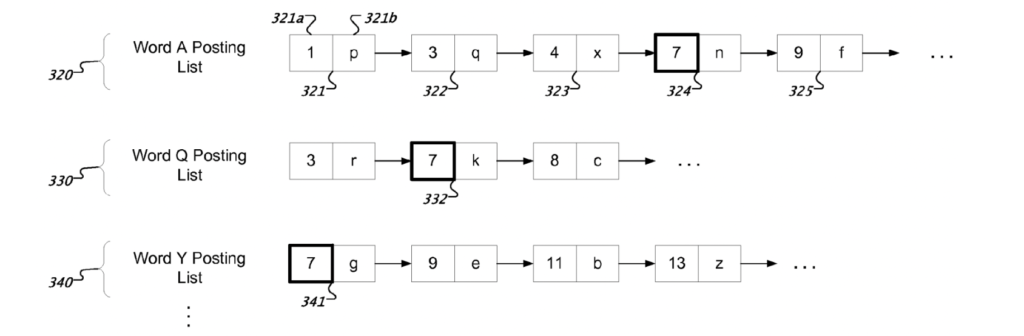
For one or more of the top ranked documents, the indexer extracts individual terms from the text and store them in a posting list.
In the posting list, each word is stored along with an index, a list of documents where the word is used, and the position of the word in the document.
Wrap-Up
What SEOs Can Do About It?
We now know that Google looks at content, URLs, and redirections to evaluate duplicates.
To make sure to minimize duplicate detection on large website, SEOs can:
- Make sure content is different enough
- Have well-structured, descriptive URLs with few parameters
- Minimize Redirections
Make sure content is different enough
If you have a website heavily impacted by duplicate content (e.g. lots of Duplicate without user-selected canonical in Google Search Console indexation report), make sure that your content have enough content that differentiate each page.
Many websites have a lot of similar category or list pages that may have been generated automatically at scale.
- Have Descriptive H1s and Titles
- Have portions of pages that don’t change often and are differentiators (see: aged documents)
- Follow recommendation in this incredible article on category pages
Have well-structured, descriptive URLs with few parameters
VERY IMPORTANT note here. Don’t change entire architecture of URLs to follow these guidelines, this is almost always destructive. Instead, adapt to how your website is built, and carefully plan URLs when building product.
- Don’t try to index www and non-www URLs
- Make sure the proper redirections from http to https are made
- Prefer event-based tracking over parameter-based tracking if possible.
- Prefer clean URLs over parameters when possible.
- Use descriptive URL. If you own siteA.com and siteB.com, maybe not a good idea to build your URL structure such as siteA.com/siteb/*.
Minimize Redirects
Clean redirection your chains.
If you have a website where A Redirects to B > C > D > E, then fix your site for A to redirect to E. T
his will reduce risk of Google clustering more URLs together. This is especially important for cross-domain linking.
A real-world example is when you work for a company with a lot of history.
BrandA.com became BrandB.com, then BrandB.com/productA became BrandB.com/productB, then BrandB.com/productB became ProductB.com.
The redirect goes like this
brandA.com/producta > brandB.com/producta > brandB.com/productb > productb.comBut somehow, historically, Google detected that brandB.com/productA was an exact duplicate of distribution-site.com.
Based on this, for a while, productb.com may be considered a duplicated of distribution-site.com.
Thus, try to clean historical redirect chains as much as possible.
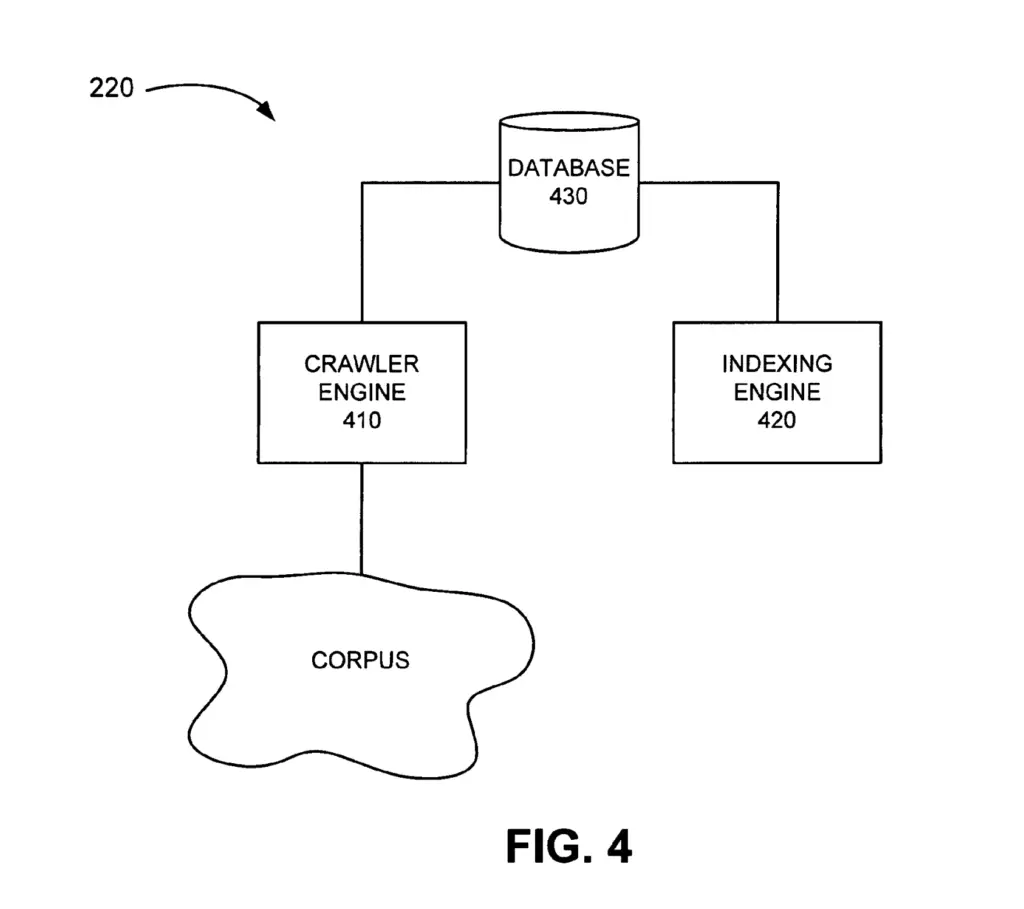
De-Duplication within the Crawler/Indexer System
De-duplication as represented in the current patent is done as part of the crawler/indexer system.
While the current patent combines the crawler and the indexer system as a single entity, they could potentially be two separated entities.
In the crawler/indexer system, data is stored in a database.
Below is a pruned example of the crawler/indexer system. Additional components may exist within the system architecture (e.g. document age analyzer, crawl skew analyzer, etc.).
What Categories is the Patent About?
- Duplication
- Clustering
Definitions
| Patent term | Definition |
|---|---|
| Document | Any machine-readable and machine-storable work product |
| Quality information | Any information useful in scoring, indexing or serving a document |
| Target documents | Destination address of a redirected URL |
| Duplicate Detector | Software that compares document and cluster them together |
| Representative Selector | Software that selects the representative document (canonical) in a cluster |
Google Search Infrastructure Involved
The Predictive-based clustering with representative redirect targets patent mentions these elements from the Google Search Infrastructure:
- Crawler/Indexer System
- Indexing engine (indexer)
- Duplicate Detector
- Representative Selector
- Indexer
- Crawler Engine
- Spider
- Content Manager
- Indexing engine (indexer)
- Database
De-Duplication Indexing FAQ
Google checks for URL patterns, redirects targets, and content checksum to cluster duplicate documents together.
Google may cluster two very similar pages, or even, in some cases, very dissimilar pages together, and thus never serve duplicate pages.
SEO may prevent duplicate detection by enhancing content on their page, by reducing intermediary redirections to other domains and by making sure URLs are descriptive and not duplicate
Patent Details
| Name | Predictive-based clustering with representative redirect targets |
| Assignee | Google LLC |
| Filed | 2008-03-31 |
| Status | Active |
| Expiration | 2031-03-16 |
| Application | 14/949,308 |
| Inventor | Jeff Cox, Mike Turitzin and David Michael Proudfoot |
| Patent | US8661069B1 |
Conclusion
In this tutorial, we have learned how Google Indexing Engine may decide to cluster duplicate or near-duplicate documents together.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.