This introduction to machine learning tutorial will give you the theory and the tools to help you learn what is machine learning,

What is Machine Learning
Machine learning (ML) is the use of computer algorithms and statistical methods to help computers learn and make decisions from data, without human supervision.
Machine learning is a branch of Artificial Intelligence (AI) and a major component of data science. See the difference between AI, Machine Learning and Deep Learning.
Machine Learning Examples
Machine learning, a subset of artificial intelligence, can be used in any field where data is involved. It has found applications across various industries and domains. From healthcare, E-commerce to improving our daily lives machine learning is currently being used at a faster pace than ever before.
Here are real-world examples of the application of machine learning:
- Image Recognition
- Classification
- Forecasting
- Information Retrieval
- Generative AI (Text, Image, Video, Music, etc.)
Read this article for specific machine learning examples.
Common Machine Learning Tasks
Below are common machine learning tasks that you may be interested in learning about.
- Natural Language Processing (NLP)
- Classification
- Clustering
- Forecasting
How to Learn Machine Learning?
It is possible for absolute beginners to learn machine learning.
The two main advices I have for you to learn machine learning (by my own experience) is to:
- Choose a programming language and stick to it: Python or R. I prefer Python for its versatility.
- Find a Course Program. I found it was easier to learn machine learning with a dedicated program. I’ve learned through Datacamp and always was satisfied. You can also check out some of the Free Github Repositories to learn data science.
Types of Machine Learning
The 5 main types of machine are:
- Supervised Learning
- Unsupervised Learning
- Semi-Supervised Learning
- Self-Supervised learning
- Reinforcement Learning
What is Supervised Learning?
Supervised learning defines an algorithm used in machine learning to train models based on labelled data. Supervised learning is most commonly used for classification and regression problems.
- Supervised learning
- Classification
- Use cases: Image classification, Customer retention
- Regression
- Use cases: Marketing forecasting, Weather forecasting
- Classification
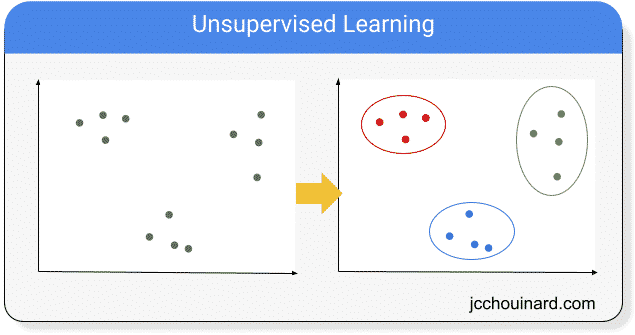
What is Unsupervised Learning?
Unsupervised learning is one of the techniques used in machine learning to train models by finding patterns in unlabelled data. Unsupervised learning is most commonly used for clustering and dimensionality reduction problems.
- Unsupervised learning
- Clustering
- Use cases: Recommender systems, targetted marketing, Query clusters, Customer segmentation
- Dimensionality reduction
- Use cases: model performance
- Clustering
What is Semi-supervised Learning?
Semi-supervised learning has attributes common to both supervised and unsupervised learning. In semi-supervised learning, part of training data is labelled while the rest is not. Semi-supervised learning is most commonly used in problems that involve large datasets where it would be too resource-intensive to label all the data.
What is Self-supervised Learning?
While semi-supervised learning requires at least some of the data points to be labelled, self-supervised learning requires no labelled data. Instead, it relies on the underlying structure of the data to make predictions.
What is Reinforcement Learning?
Reinforcement learning is a type of machine learning that train models to make a sequence of decisions by maximizing the total reward. It is most commonly used in AI and robotics.
Machine Learning Algorithms
There are a lot of different machine learning algorithms, and some would fall into multiple categories, but I created a mind-map to help visualize the most important machine learning algorithms.
This is just to get a global picture of machine learning and should not be used as a source of truth. For instance, Logistic regression could be both a Classification and a Regression algorithm.
Below shows a table of content format with links to the algorithms that I have written about.
- Supervised learning
- Regression algorithms
- Ordinary Least Squares (OLS)
- Linear Regression
- Logistic Regression
- Classification Algorithms
- k-nearest neighbors (KNN)
- Support vector machines (kernel machines)
- RBF networks
- Regularization algorithms
- Ridge Regression
- Lasso Regression
- Elastic Net
- Regression algorithms
- Unsupervised Learning
- Dimensionality reduction algorithms
- Principal component analysis (PCA)
- Non-negative matrix factorization (NMF)
- Linear discriminant analysis (LDA)
- T-distributed stochastic neighbor embedding (t-SNE)
- Generalized discriminant analysis (GDA)
- Autoencoder
- Kernel PCA
- Clustering algorithms
- K-means
- Hierarchical Clustering
- DBSCAN
- Fuzzy C-Means
- Dimensionality reduction algorithms
- Decision Tree algorithms
- ID3
- C4.5
- Classification and regression trees (CART)
- CHAID
- MARS
- Ensemble algorithms
- Random Forest
- Boosting
- Bootstrap Aggregation (Bagging)
- Stacked generalization (Blending)
- Deep Learning algorithms
- Convolutional Neural Networks (CNN)
- Recurrent Neural Networks (RNN)
- Long Short-Term Memory (LSTM)
- Deep Belief Networks (DBN)
- Autoencoder
- Deep Boltzmann Machines (DBM)
- Neural networks algorithms
- Radial Basis Function Network (RBFN)
- Perceptron
- Back-propagation
- Bayesian algorithms
- Naive Bayes
- Gaussian Naive Bayes
- Causal Impact
Popular Machine Learning Libraries in Python
There are a number of machine learning libraries available in Python.
| Name of Library | Popular Modules | Alternatives | Difficulty to Learn | Specialization |
|---|---|---|---|---|
| OpenAI | GPT-3, Codex | LLaMA, BERT | High | NLP, AI Research |
| Scikit-learn | Classification, Regression | XGBoost, LightGBM | Low | General ML |
| NLTK | Tokenization, POS Tagging | spaCy, TextBlob | Moderate | NLP |
| spaCy | tokens, displacy | nltk, TextBlob | Easy | NLP |
| TensorFlow | Keras, tf.data | PyTorch, MXNet | High | Deep Learning |
| PyTorch | Tensors, Autograd | TensorFlow, MXNet | Moderate | Deep Learning |
| Keras | Sequential, Functional API | TensorFlow, PyTorch | Moderate | Deep Learning |
Data Science and Machine Learning Process
A machine learning process is an iterative process that data scientists follow to improve their decision-making through better analysis, visualization, interpretation and modelling of their data.
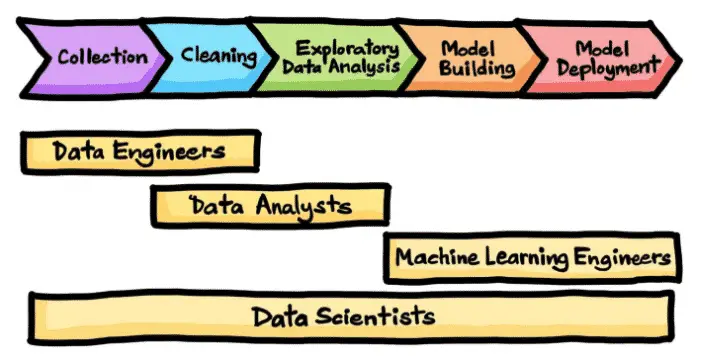
Depending on the role, the process may vary, but altogether following this “typical” process help to increase confidence in the results.
- Problem definition
- Data collection
- Data preparation
- Exploratory data analysis (EDA)
- Data preprocessing
- Feature engineering and feature selection
- Model preparation
- Split into training and testing sets
- Hyperparameter tuning
- Cross validation
- Model training
- Model evaluation
- Precision-Recall curve
- ROC curve
- Model selection
- Model deployment
Who Can Leverage Machine learning?
- Machine learning for SEO
- Machine learning in Data Science
- Machine Learning for Scientists
- Machine Learning in Finance
- Machine Learning in E-commerce
- Machine Learning in Job Search
- Machine Learning in Image Recognition
How to Gather Data for Machine Learning
Machine learning requires a lot of data to produce prediction that can be used. Hence, data scientists use many techniques for gathering data to train their machine learning models.
There are three main ways to gather data for machine learning:
- Internal Data
- APIs
- Web Scraping
Internal Data for Machine Learning
There are many sources of internal data that can be used to train machine learning models. From Google Analytics data to customer sales data or even data that your business gathers from things like video cameras, all can be used in Machine learning.
APIs for Machine Learning
Machine learning engineers and data scientists often use application programming interfaces such as the Reddit API or the Wikipedia API to gather publicly available data to train their machine learning models. Internal APIs such as the Google Search Console API can be used to gather internal data too.
Web Scraping for Machine Learning
Web scraping is an essential technique used by data scientists to gather data for machine learning. It provides a way to automate data gathering from the Internet and is the basis of how Large Language Models were all built.
Useful Skills for Machine Learning
There are some important skills that data scientists and machine learning engineers should have:
- Python programming
- SQL
- Version Control and Git
- Knowledge of Mathematics and Statistics
Machine Learning Books
Hands-on machine learning with scikit-learn keras and tensorflow by Aurélien Geron
Who to Follow in the Machine Learning Community?
Here is an amazing list of people who are shaping Machine Learning community:
- Santiago
- Mark Tenenholtz
- Pratham Prasoon
- Sayan Nath
- Prashant
- Jean de Nyandwi
- Matthias Niessner
- Andrew Trask
- Jake VanderPlas
- Sayak Paul
- JFPuget
- Alejandro Piad Morffis
- Gus
- Vincent D. Warmerdam
- Josh Gordon
- Jason Brownlee
- François Chollet
- Aurélien Geron
- Philip Vollet
Alternatively, you can follow this machine learning list on Twitter.
Conclusion
In this introduction to machine learning, we have learned what machine learning is and how it is different to AI. We also have covered the types of machine learning and which algorithms can be used for each type.
Finally, we have seen what the data science process is and why it is important.
Now, I sure hope that you will keep learning machine learning and share your progress as you go. Good luck.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.